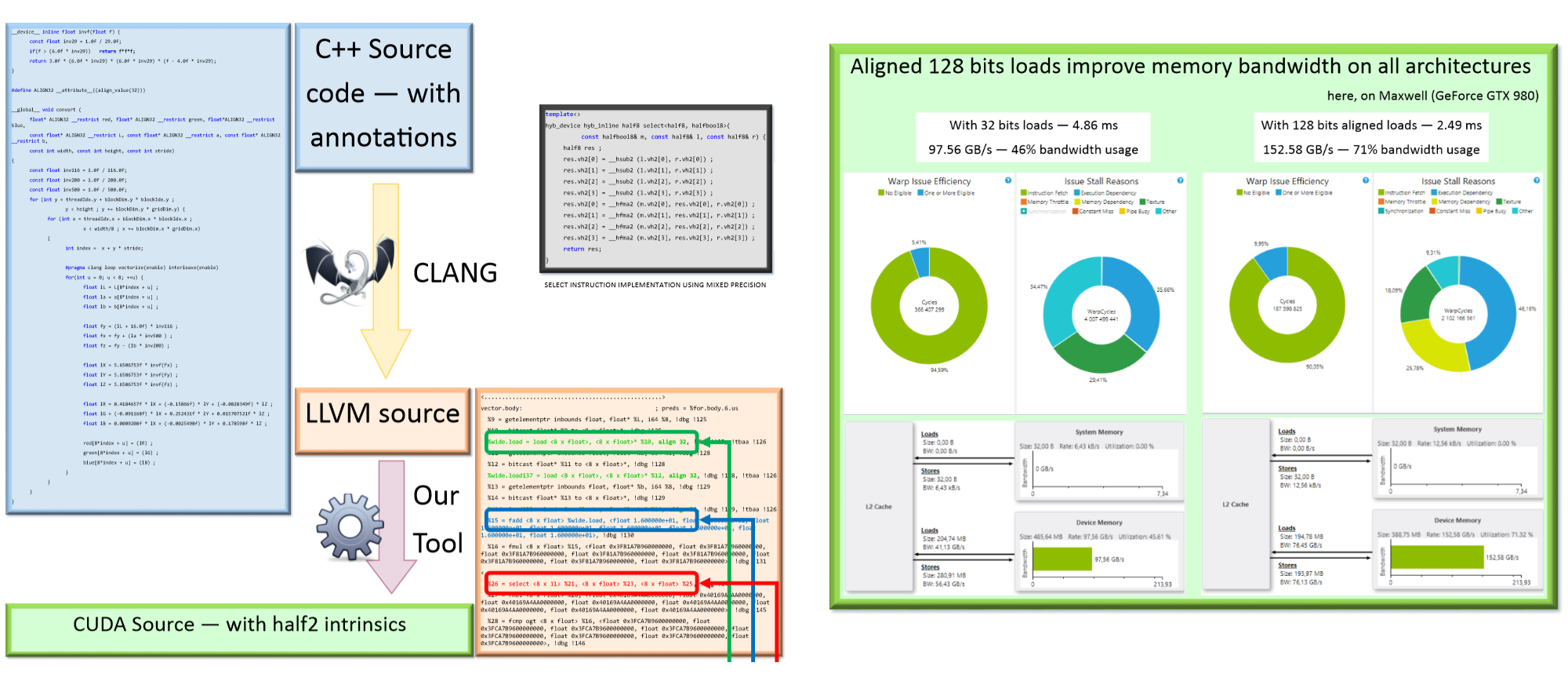
At Supercomputing 2015, NVIDIA announced Jetson TX1, a mobile supercomputer, offering up to 1 TFLOPs of compute power for a power envelope typical of embed-ded devices. Targeting image processing and deep learning, this platform is the first available to natively expose mixed precision instructions. However, the new mixed precision unit requires that operations on 16-bit precision floating points are done in pairs. Hence, approaching peak performance level requires usage of the half2 type which pairs two values in a single register.
In this work, we present an approach that makes use of existing vectorization tool developed for CPU code optimization to further generate CUDA source code that uses half2 intrinsic functions, hence enabling mixed precision hardware usage with little effort. Using this approach, we are able to generate efficient CUDA code from a single scalar version of the code.
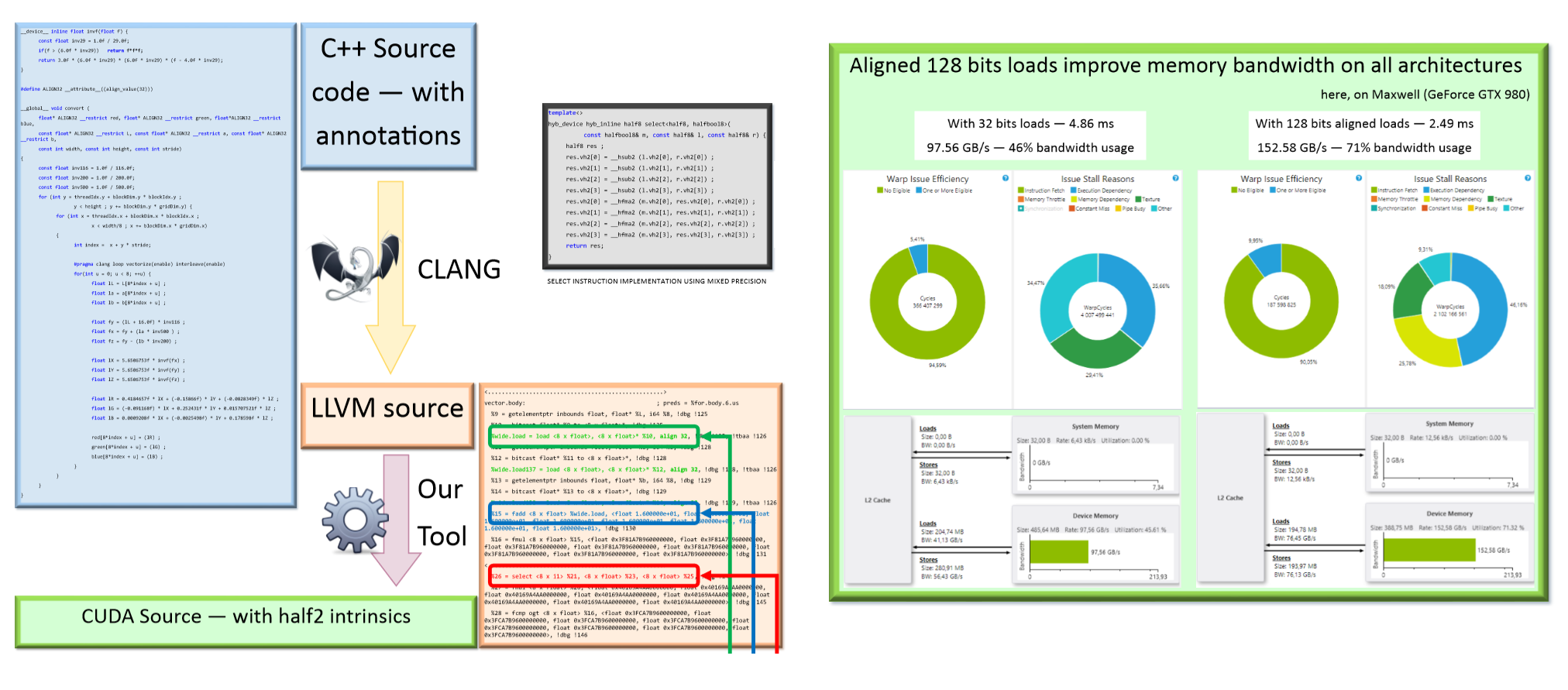
This source to source code translation may be used in many application fields for different numeric types. Moreover, this approach shows very nice boundary effects such as better memory access pattern and instruction level parallelism.
{kind=link}