I write down here stuff I did and want to keep track of.
CUDA – Unified memory (Pascal at least)
Can I ensure that NVCC has managed to place an array in registers?
Hybrid Vector Library—From Memory Bound to Compute Bound with NVVM
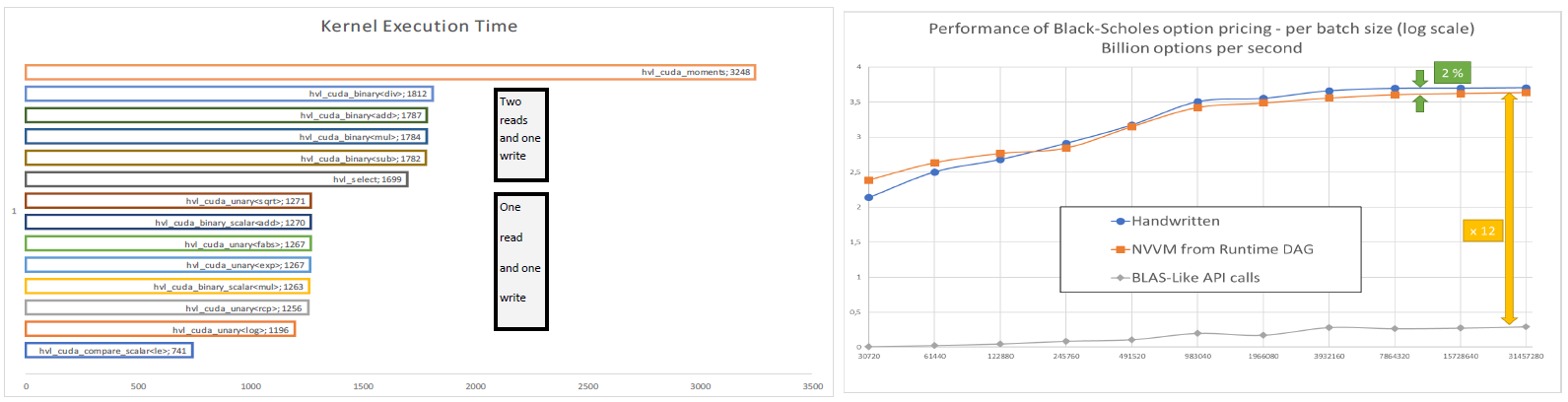
When submitting small tasks to the GPU, grid scheduling and synchronization costs may be much higher than computations, even on a CPU. In this case, the benefit of GPU computing is lost. Leveraging runtime compilation, we illustate an approach that generates source code to replace a list of library API calls into a single kernel call. The benefits are twoflod: (1) scheduling costs are reduced to a minimum, result of merging several calls into a single one, (2) execution on vector of values of an aggregate kernel result in a compute-bound implementation.
Performance Out of the Box on Multicore and Manycore Hardware with Code Modernization
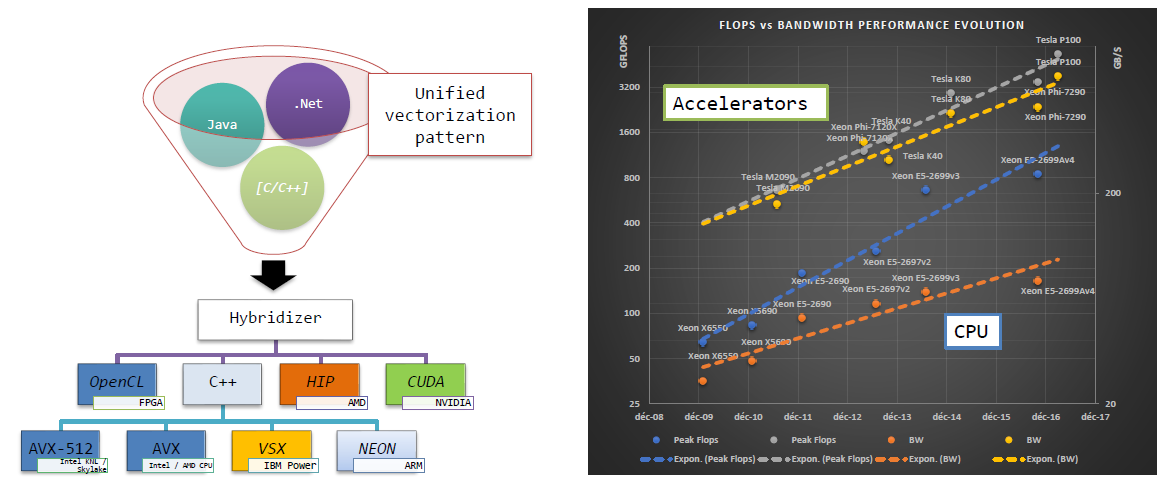
We presented at TES 2017 why code modernization is a requirement to benefit from current and future architectures, as well as how Hybridizer can help modernize code with little effort.
How Pascal And Power 8 Will Accelerate Counterparty Risk Calculations
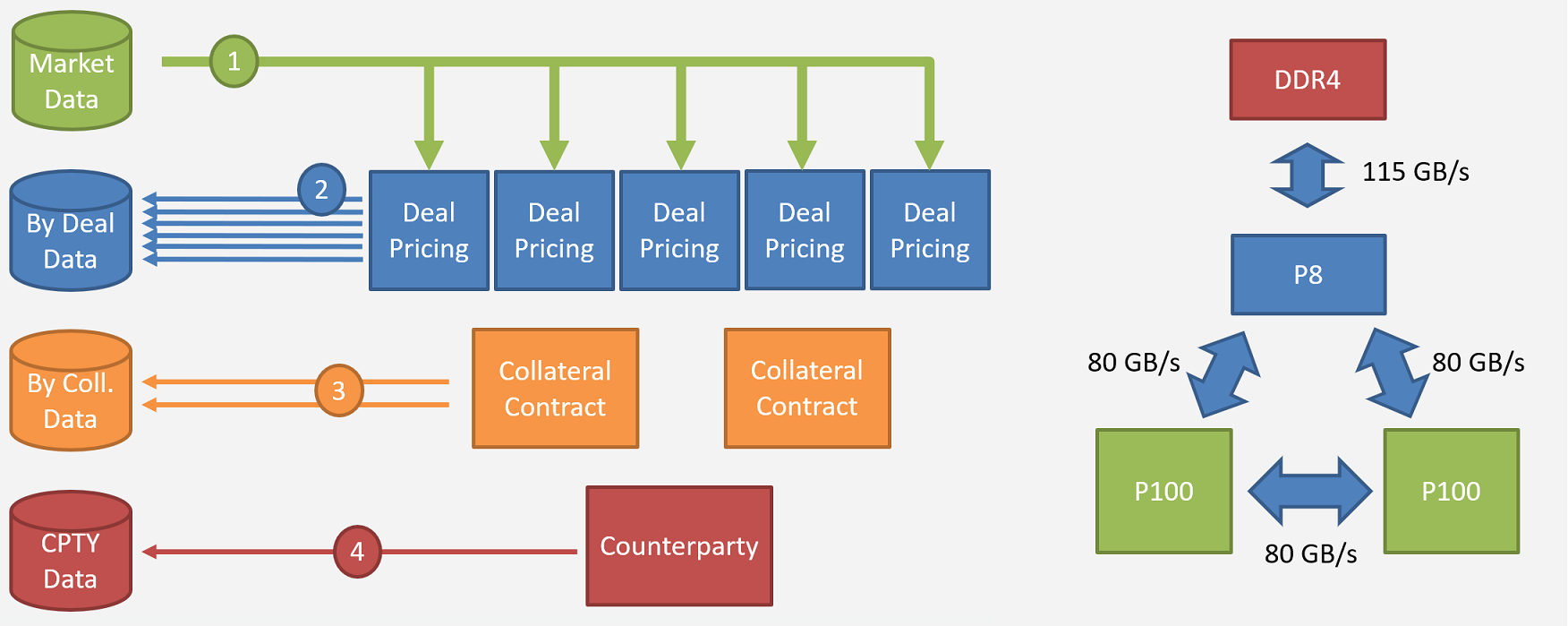
Since the financial crisis of 2008, regulators have been increasingly demanding in terms of risk analysis and stress scenario simulations. In this talk, we present an approach for counterparty risk calculations based on Directed Acyclic Graphs. Calculations are arranged in a tree, where nodes are simulation parts. Nodes hold temporary data that may be reused for other calculations further in the graph. This technique offers great flexibillity, benefits from hardware capability improvements and is resilient to new regulatory requirements and demands. We will illustrate the potential benefits of Pascal according to performance expectations of NVLink, and how these features are helpful in the DAG compute environment.
Cuda: Declaring a device constant as a template
Is it possible to access hard disk directly from gpu?
CPU and GPU differences
Java Image Processing: How Runtime Compilation Transforms Memory-Bound into Compute-Bound
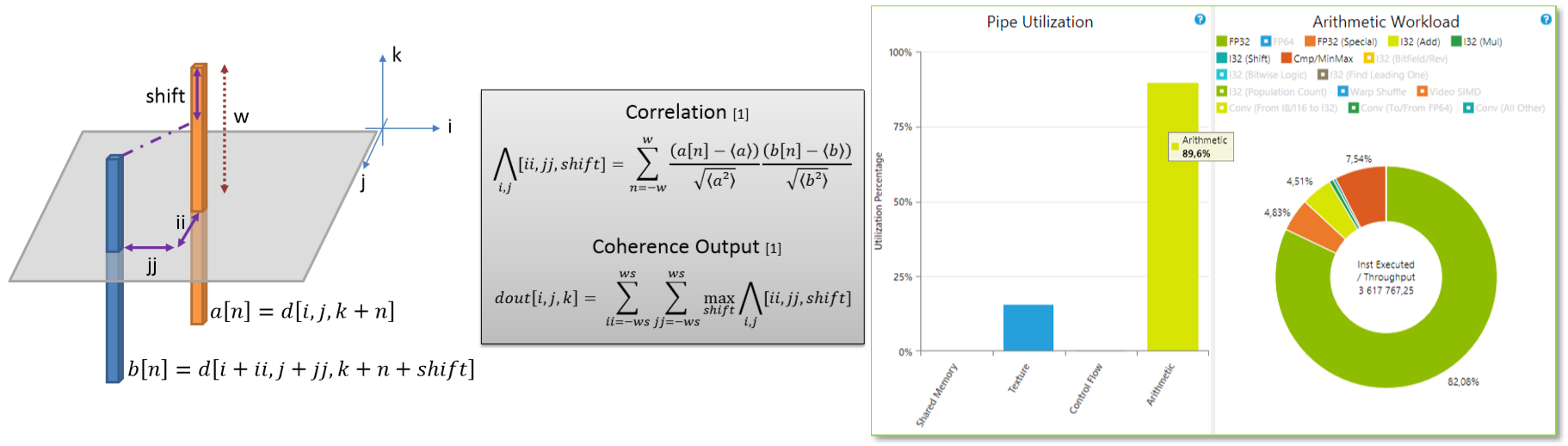
A wide variety of image processing algorithms are typically parallel. However, depending on filter-size or neighborhood search pattern, memory access is critical for performances. We’ll show how loop reordering and memory locality fine-tuning help achieve best performance. Using Hybridizer to automate Java byte-code transformation to CUDA source code, and using new CUDA feature Run Time Compilation, we transformed execution from memory-bound to compute-bound. Applying this technique to oil and gas image processing algorithms results in interactive response time on production-size datasets.
Presented at GTC 2016 – ID S6314