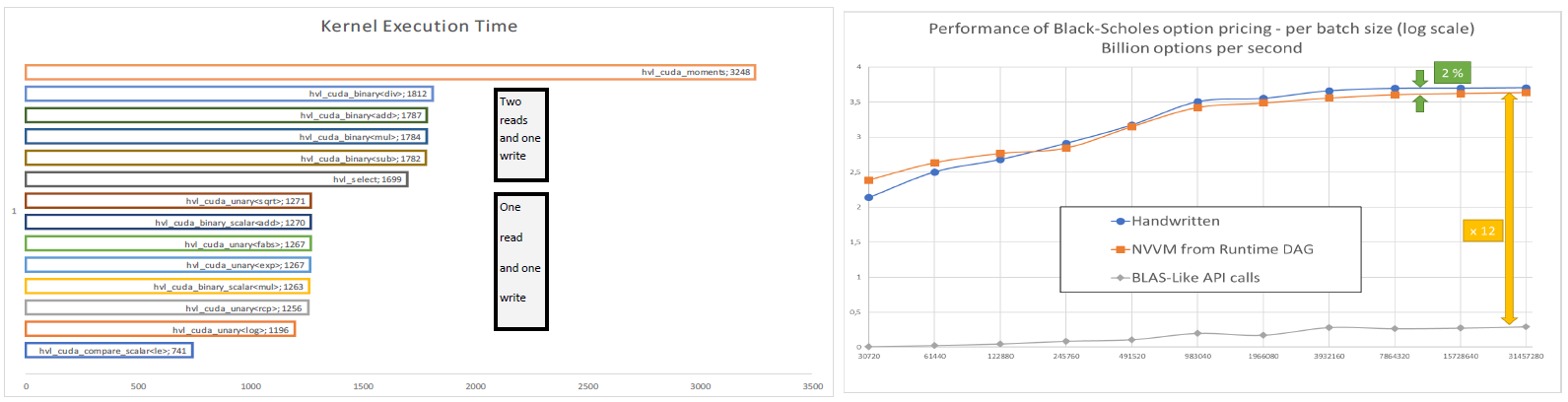
When submitting small tasks to the GPU, grid scheduling and synchronization costs may be much higher than computations, even on a CPU. In this case, the benefit of GPU computing is lost. Leveraging runtime compilation, we illustate an approach that generates source code to replace a list of library API calls into a single kernel call. The benefits are twoflod: (1) scheduling costs are reduced to a minimum, result of merging several calls into a single one, (2) execution on vector of values of an aggregate kernel result in a compute-bound implementation.